
Research overview
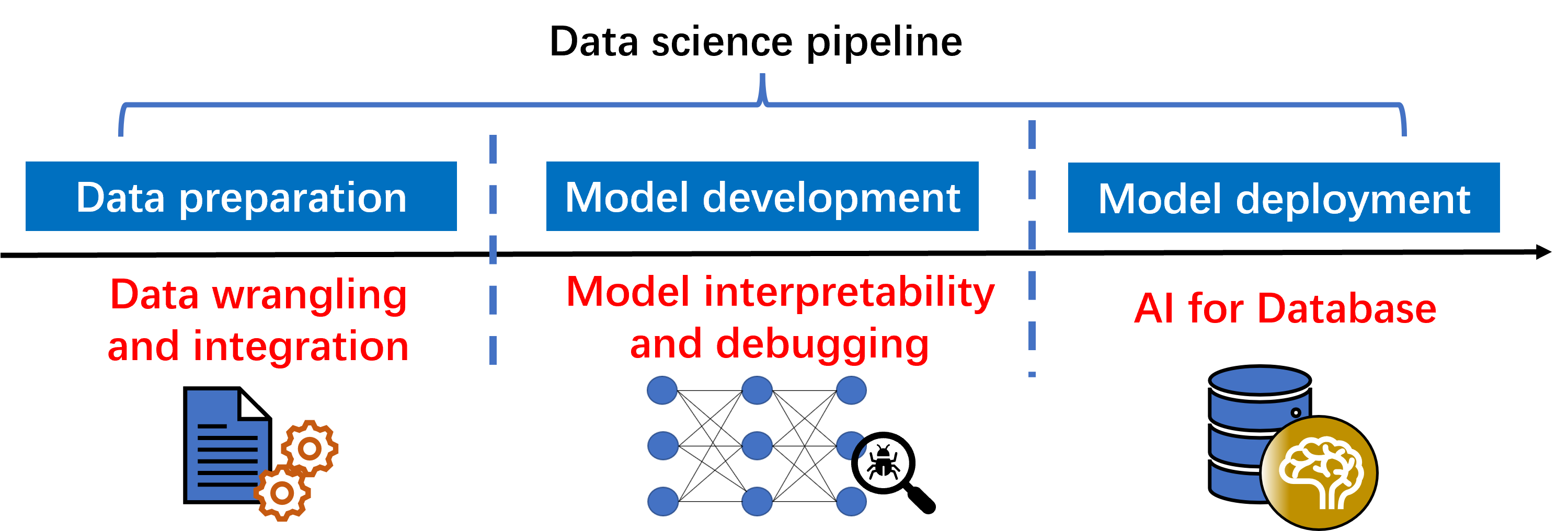
My research interests primarily lie at the intersections of database systems, data science and AI. Specifically, my research work spans three inter-dependent lines, covering different stages of general data science pipelines. A comprehensive data science pipeline includes the stages for constructing and utilizing machine learning models in real applications, which is usually composed of three phases, i.e., data preparation phase, model development phase and model deployment phase.
The first line of my research delves into addressing emerging data management problems occuring in the data preparation phase, including data wrangling and data integration problem. The overarching objective is to enhance model performance through improving data quality, ultimately reducing the cost and human efforts associated with the broader utilizations of AI.
The second facet of my research is on interpretating and debugging machine learning models during the model development phase. This usually involves dealing with some pivotal questions from data-centric perspective, such as identifying the significancy of individual training samples and developing solutions to capture and rectify critical model errors across a large dataset. Tackling those research challenges is imperative for achieving trustworthy AI in high-stake areas, e.g., health care and self-driving.
The third part of my research is on deploying machine learning models on realistic applications, specifically in the realm of AI for database. One key focus is on harnessing machine learning techniques, such as large language models, to automate the process of debugging the performance of database systems. This aims at alleviating the workload of Database Administrators (DBAs) in real-world database products.